
一、强化学习概念
强化学习(Reinforcement learning,RL)讨论的问题是一个智能体(agent) 怎么在一个复杂不确定的 环境(environment) 里面去极大化它能获得的奖励。通过感知所处环境的 状态(state) 对 动作(action) 的 反应(reward), 来指导更好的动作,从而获得最大的 收益(return),这被称为在交互中学习,这样的学习方法就被称作强化学习。强化学习核心就是学习两个东西:1、策略函数Policy = π(s,a)=π(a∣s)=P(At=a∣St=s).另一个就是最优价值函数(动作价值函数和状态价值函数)
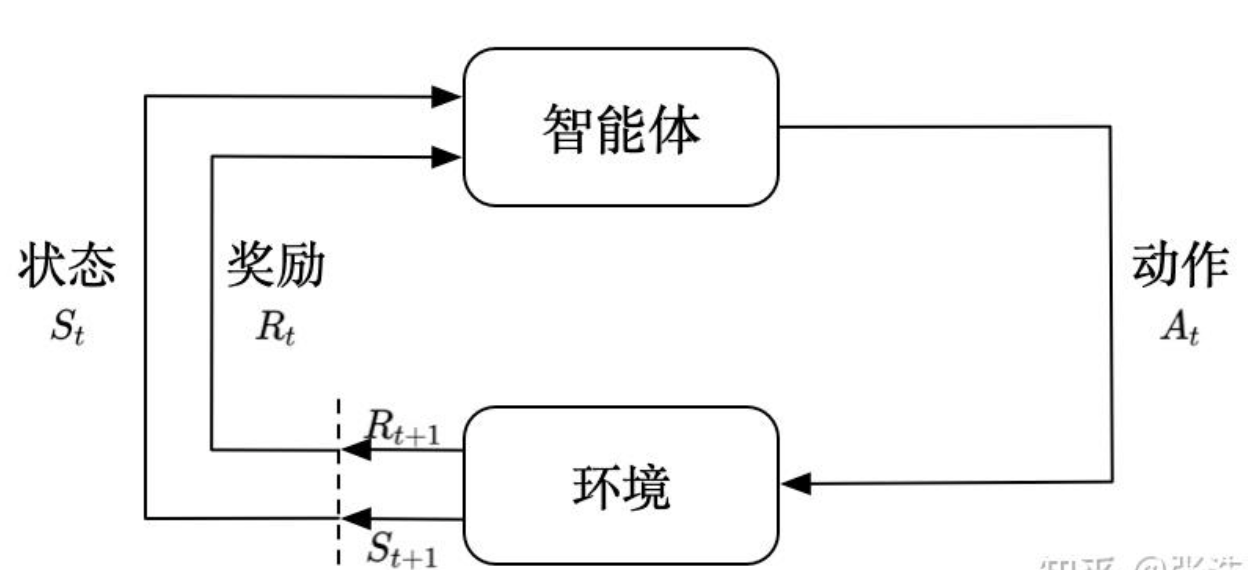
在强化学习过程中,智能体跟环境一直在交互。智能体在环境里面获取到状态,智能体会利用这个状态输出一个动作,一个决策。然后这个决策会放到环境之中去,环境会根据智能体采取的决策,输出下一个状态以及当前的这个决策得到的奖励。智能体的目的就是为了尽可能多地从环境中获取奖励。
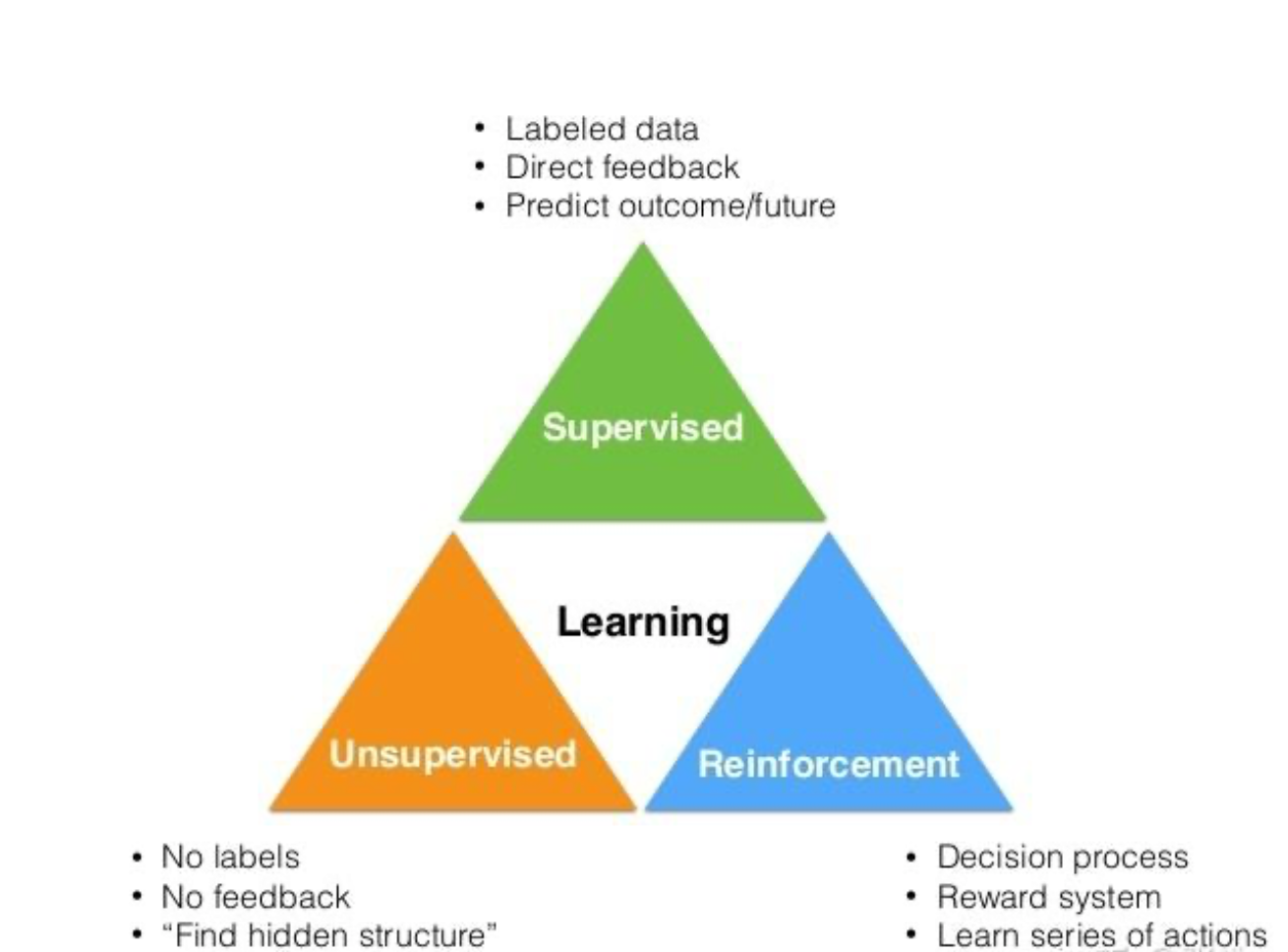
强化学习是除了监督学习和非监督学习之外的第三种基本的机器学习方法。
监督学习 是从外部监督者提供的带标注训练集中进行学习。 (任务驱动型)
非监督学习 是一个典型的寻找未标注数据中隐含结构的过程。 (数据驱动型)
强化学习 更偏重于智能体与环境的交互, 这带来了一个独有的挑战 ——“试错(exploration)”与“开发(exploitation)”之间的折中权衡,智能体必须开发已有的经验来获取收益,同时也要进行试探,使得未来可以获得更好的动作选择空间。 (从错误中学习)
强化学习主要有以下几个特点:
试错学习:强化学习一般没有直接的指导信息,Agent 要以不断与 Environment 进行交互,通过试错的方式来获得最佳策略(Policy)。
延迟回报:强化学习的指导信息很少,而且往往是在事后(最后一个状态(State))才给出的。比如 围棋中只有到了最后才能知道胜负。
二、强化学习核心术语
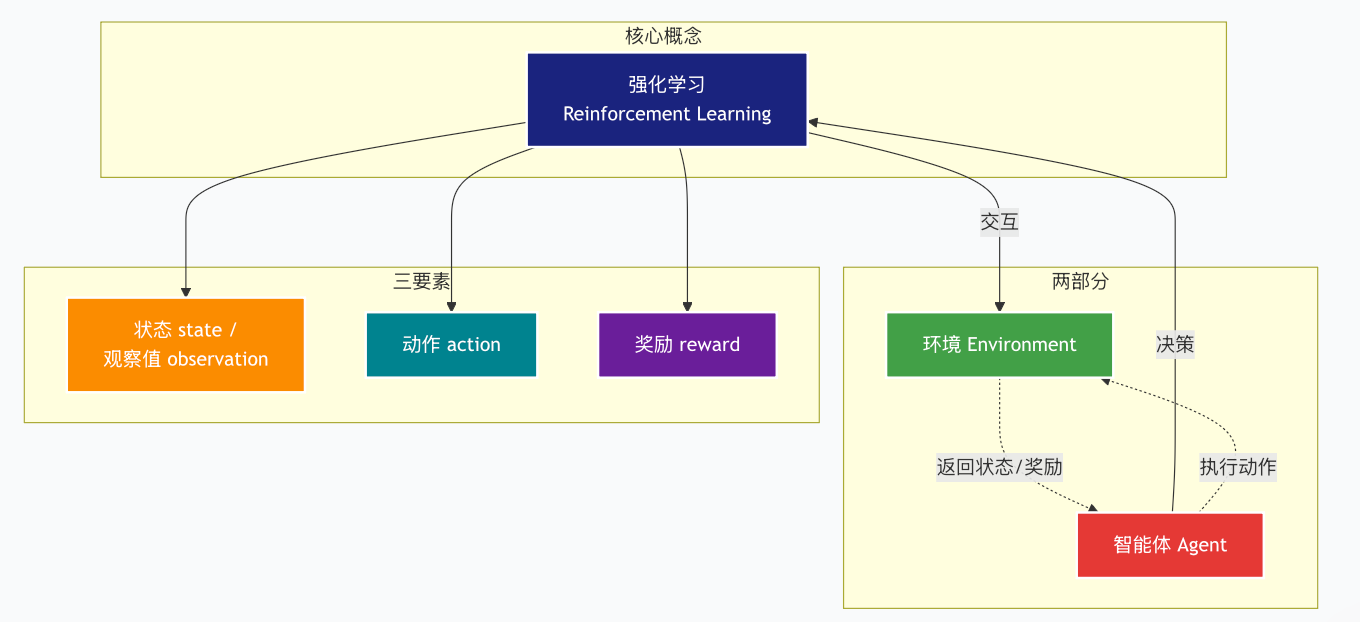
环境(Environment) 是一个外部系统,智能体处于这个系统中,能够感知到这个系统并且能够基于感知到的状态做出一定的行动。
智能体(Agent) 是一个嵌入到环境中的系统,能够通过采取行动来改变环境的状态。
状态(State)/观察值(Observation):状态是对世界的完整描述,不会隐藏世界的信息。观测是对状态的部分描述,可能会遗漏一些信息。
动作(Action):不同的环境允许不同种类的动作,在给定的环境中,有效动作的集合经常被称为动作空间(action space),包括离散动作空间(discrete action spaces)和连续动作空间(continuous action spaces),例如,走迷宫机器人如果只有东南西北这 4 种移动方式,则其为离散动作空间;如果机器人向 360◦ 中的任意角度都可以移动,则为连续动作空间。
奖励(Reward):是由环境给的一个标量的反馈信号(scalar feedback signal),这个信号显示了智能体在某一步采 取了某个策略的表现如何。
策略(Policy):策略是智能体用于决定下一步执行什么行动的规则。
1、确定性策略:在给定状态下,智能体总是执行同一个确定的动作。一般表示为:a=π(s)a=π(s)
2、随机策略:在给定状态下,智能体以一定概率分布选择动作。一般表示为:a∼π(⋅∣s)a∼π(⋅∣s),其中 $\pi(a \mid s)$ 表示在状态 s下选择动作 a 的概率。
状态转移(State Transition):状态转移描述了环境在智能体执行动作后如何变化的过程。状态转移可以是确定的,也可以是随机的,通常假设为随机过程,其随机性来源于环境的不确定性。状态转移可以用状态转移密度函数来表示:p(s′∣s,a)p(s′∣s,a)上式表示:在当前状态 $s$ 下执行动作 $a$ 后,环境转移到下一个状态 s' 的概率密度。
注意:环境的变化规律通常是未知的,这也是强化学习需要与环境交互学习的原因。
轨迹:动作-状态-激励链
回报(Return):回报又称累积未来奖励(Cumulated Future Reward),一般用 U 表示,定义为:U=Rt+Rt+1+Rt+2+⋯+RTU=Rt+Rt+1+Rt+2+⋯+RT 。。 其中 R_t 表示第 t 时刻获得的即时奖励,T 为终止时刻。智能体的目标就是最大化回报 U。
折扣回报(Discounted Return):由于未来的奖励往往不如当前等值的奖励更有价值(即时间偏好),因此通常对未来的奖励赋予更低的权重。引入折扣率 $\gamma \in [0, 1]$,折扣回报定义为:Ut=Rt+γRt+1+γ2Rt+2+⋯=∑k=0∞γkRt+kUt=Rt+γRt+1+γ2Rt+2+⋯=k=0∑∞γkRt+k,,, 当 $\gamma = 0$ 时:只关心当前奖励(短视)。当 $\gamma = 1$ 时:平等看待所有未来奖励(远视)。
核心公式汇总
| 概念 | 符号 | 公式 | 说明 |
|------|------|------|------|
| 确定性策略 | a = π(s) | 状态到动作的映射 | 在状态 s 下确定执行动作 a |
| 随机策略 | a ∼ π(·\|s) | 动作概率分布 | 在状态 s 下以概率 π(a\|s) 选择动作 a |
| 回报 | U_t | U_t = Σ γᵏ R_{t+k} | 从时刻 t 开始的折扣累积奖励 |
价值函数(Value Function)
举例说明:在象棋游戏中,定义赢得游戏得 $+1$ 分,其他动作得 $0$ 分,状态是棋盘上棋子的位置。仅从 $0$ 和 $+1$ 这两个数值并不能知道智能体在游戏过程中到底下得怎么样,而通过价值函数则可以获得更多洞察。
价值函数使用期望对未来的收益进行预测:
一方面,不必等待未来的收益实际发生就可以获知当前状态的好坏;
另一方面,通过期望汇总了未来各种可能的收益情况。
使用价值函数可以很方便地评价不同策略的好坏。
状态价值函数(State-Value Function)
对于策略 $\pi$,状态价值函数 $V^\pi(s)$ 表示从状态 $s$ 开始,按照策略 $\pi$ 行动所获得的期望折扣回报:
Vπ(s)=Eπ[Ut∣St=s]=Eπ[∑k=0∞γkRt+k | St=s]Vπ(s)=Eπ[Ut∣St=s]=Eπ[k=0∑∞γkRt+kSt=s]
动作价值函数(Action-Value Function)
动作价值函数 $Q^\pi(s, a)$ 表示在状态 $s$ 下执行动作 $a$,之后遵循策略 $\pi$ 所获得的期望折扣回报:
Qπ(s,a)=Eπ[Ut∣St=s,At=a]=Eπ[∑k=0∞γkRt+k | St=s,At=a]Qπ(s,a)=Eπ[Ut∣St=s,At=a]=Eπ[k=0∑∞γkRt+kSt=s,At=a]
最优价值函数
最优状态价值函数:$V^*(s) = \max_\pi V^\pi(s)$
最优动作价值函数:$Q^*(s, a) = \max_\pi Q^\pi(s, a)$
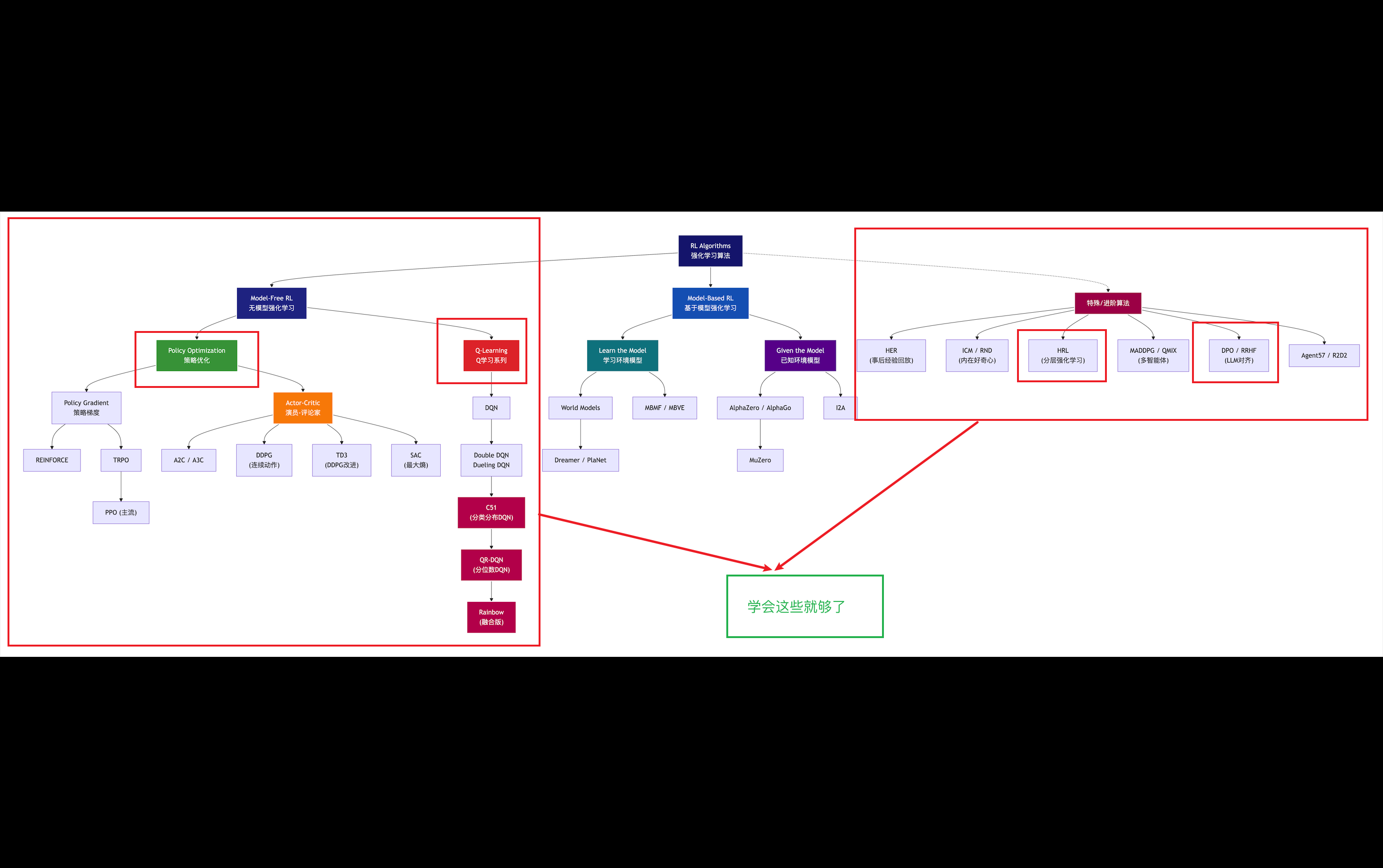
三、强化学习算法分类
目前由于分类的标准/依据和视角很多在不同的技术博客介绍中非常容易出现不同的分类标准,十分容易造成初学者的混乱,这对初学时帮助建立整体大局观十分不利,下文我讲着重从不同的分类角度/视角来展示不同标准下的强化学习算法的归类,教会你应该从啥视角去学习并着重列出初学者快速学习掌握强化学习核心的算法
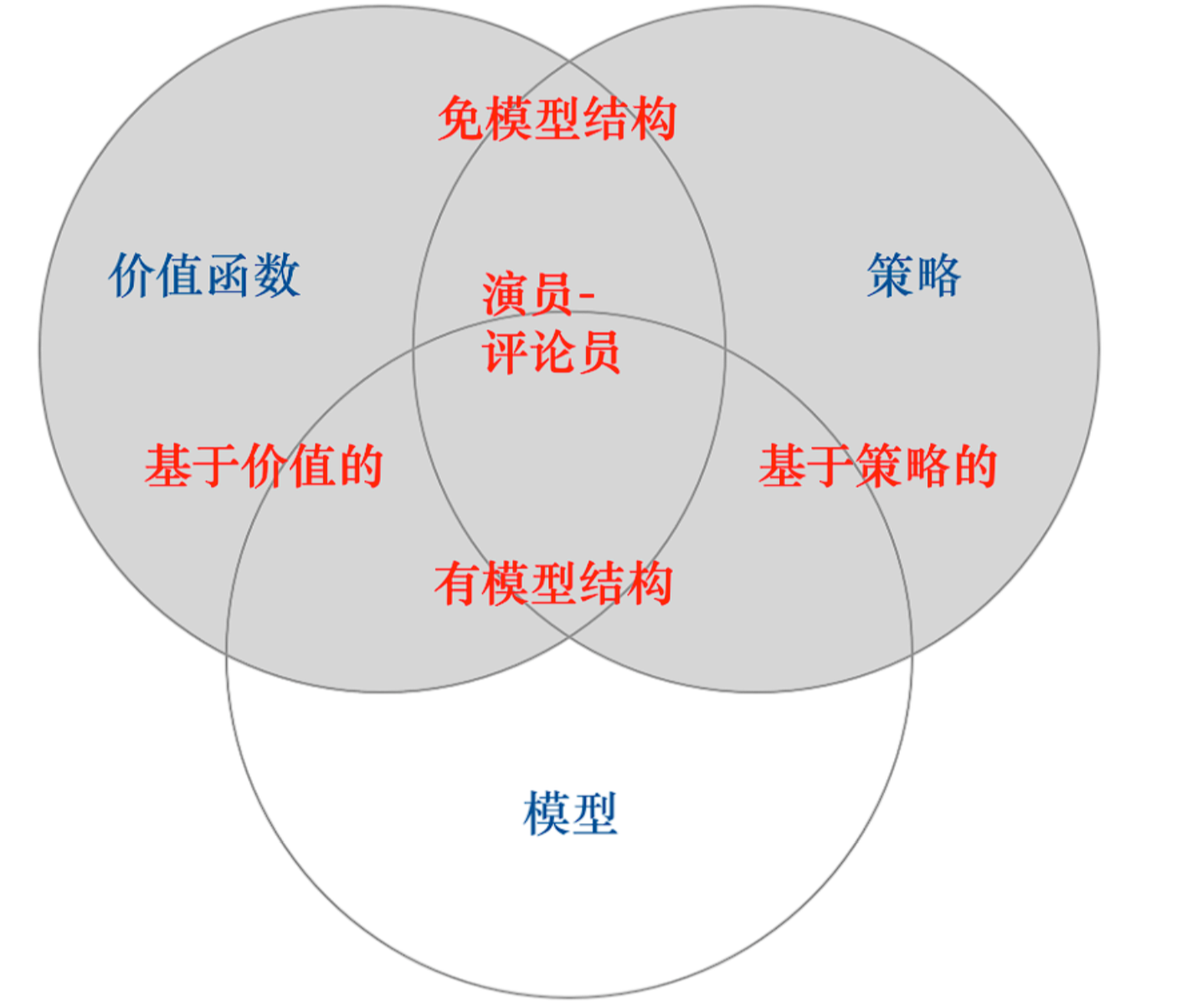
强化学习算法最顶层的分类按是否依赖环境模型(Model)来划分的:
如果再往下分一层,无模型算法内部还可以按学习内容分为三类:
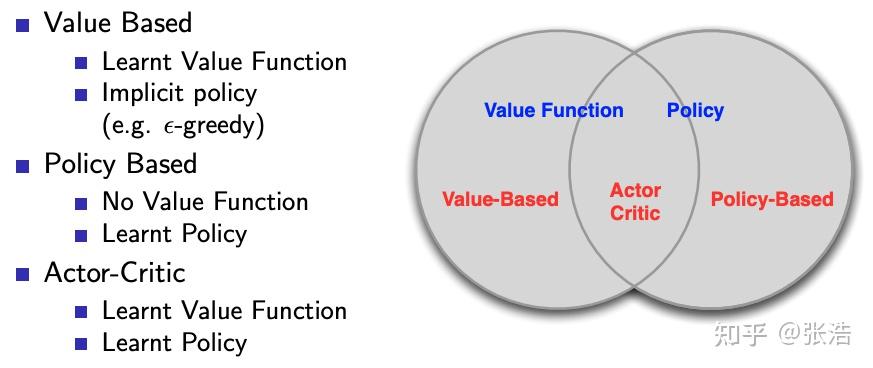
1. 基于价值(Value-based)
学习目标:直接学习 Q(s,a)Q(s,a) 或 V(s)V(s)
策略:由价值函数隐式决定(选最大 QQ 值对应的动作)
典型算法:DQN、Sarsa、Q-learning等
2. 基于策略(Policy-based)
学习目标:直接学习策略 π(a∣s)π(a∣s),不学习价值函数
策略:显式参数化,通过梯度上升优化
典型算法:REINFORCE、PPO、TRPO、A3C等
3. 演员-评论家(Actor-Critic)
学习目标:同时学习策略(Actor)和价值函数(Critic)
策略:Actor负责选动作,Critic负责评估动作好坏
典型算法:A3C、SAC、TD3、PPO(也属于此类)
RL算法分类树(部分):
强化学习算法
│
├── 有模型(Model-based)
│ ├── 动态规划(策略迭代、价值迭代)
│ ├── 基于模型的策略优化(PETS、Dreamer)
│ └── 蒙特卡洛树搜索(MCTS,如AlphaGo)
│
└── 无模型(Model-free)
├── 蒙特卡洛方法(MC)
│ └── 回合制更新,如REINFORCE(纯策略梯度)
│
└── 时序差分方法(TD)
├── 基于价值(Value-based)
│ ├── Q-learning(离线策略)
│ └── Sarsa(在线策略)
│ └── DQN、DPO
│
├── 基于策略(Policy-based)
│ └── PPO、TRPO(通常也结合价值函数)
│
└── 演员-评论家(Actor-Critic)
├── A3C、A2C
├── DDPG、TD3(连续动作空间)
└── SAC(最大熵强化学习)当前强化学习算法可以从 4 个不同的角度分类,每个角度都是有效的,但初学者容易混淆:
初学者的困境:同一个算法(比如 PPO)可以同时被归类为 Model-Free、Policy-Based、On-Policy、连续动作算法。当你看到四个不同的分类图时,自然就晕了。
三层分类法(初学者专用)
建议初学者采用三层分类法,每一层回答一个问题,层层递进:
第1层:算法解决什么问题?
↓
第2层:算法用什么方法解决?
↓
第3层:具体有哪些代表算法?
第1层:按"解决什么问题"分类(只分3类)
┌─────────────────────────────────────────────────────────────────────────────┐
│ 强化学习算法(按问题类型分类) │
├─────────────────────────────────────────────────────────────────────────────┤
│ │
│ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐ │
│ │ 离散动作问题 │ │ 连续动作问题 │ │ 模型已知问题 │ │ **大模型对齐**│ │
│ │ │ │ │ │ │ │ **与推理** │ │
│ │ 动作选项有限 │ │ 动作是连续数值 │ │ 环境规则明确 │ │ 动作空间巨大 │ │
│ │ 如:上下左右 │ │ 如:方向盘角度 │ │ 如:围棋规则 │ │ 输出是Token │ │
│ └───────┬───────┘ └───────┬───────┘ └───────┬───────┘ └───────┬───────┘ │
│ │ │ │ │ │
│ ▼ ▼ ▼ ▼ │
│ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐ │
│ │ DQN 系列 │ │ PPO/SAC │ │ AlphaZero │ │ **PPO** │ │
│ │ Q-learning │ │ DDPG/TD3 │ │ MuZero │ │ **DPO** │ │
│ │ │ │ │ │ │ │ **GRPO** │ │
│ └───────────────┘ └───────────────┘ └───────────────┘ └───────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────────────┘为什么这样分?
实际问题首先问:我的动作是什么类型?
这个分类直接对应工程选型,最实用
第2层:按"学习方法"分类(了解算法内部逻辑)
在第1层的基础上,了解每个算法内部是怎么工作的:
算法内部学习方法
│
┌─────────────────┼─────────────────┐
│ │ │
▼ ▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│ 价值学习 │ │ 策略学习 │ │ 两者结合 │
│ Value │ │ Policy │ │ Actor- │
│ Based │ │ Based │ │ Critic │
└─────────┘ └─────────┘ └─────────┘
│ │ │
▼ ▼ ▼
学 Q(s,a) 学 π(a|s) 学 Q + π
选最大Q的动作 直接输出动作 Actor做决策
Critic做评估对应关系:
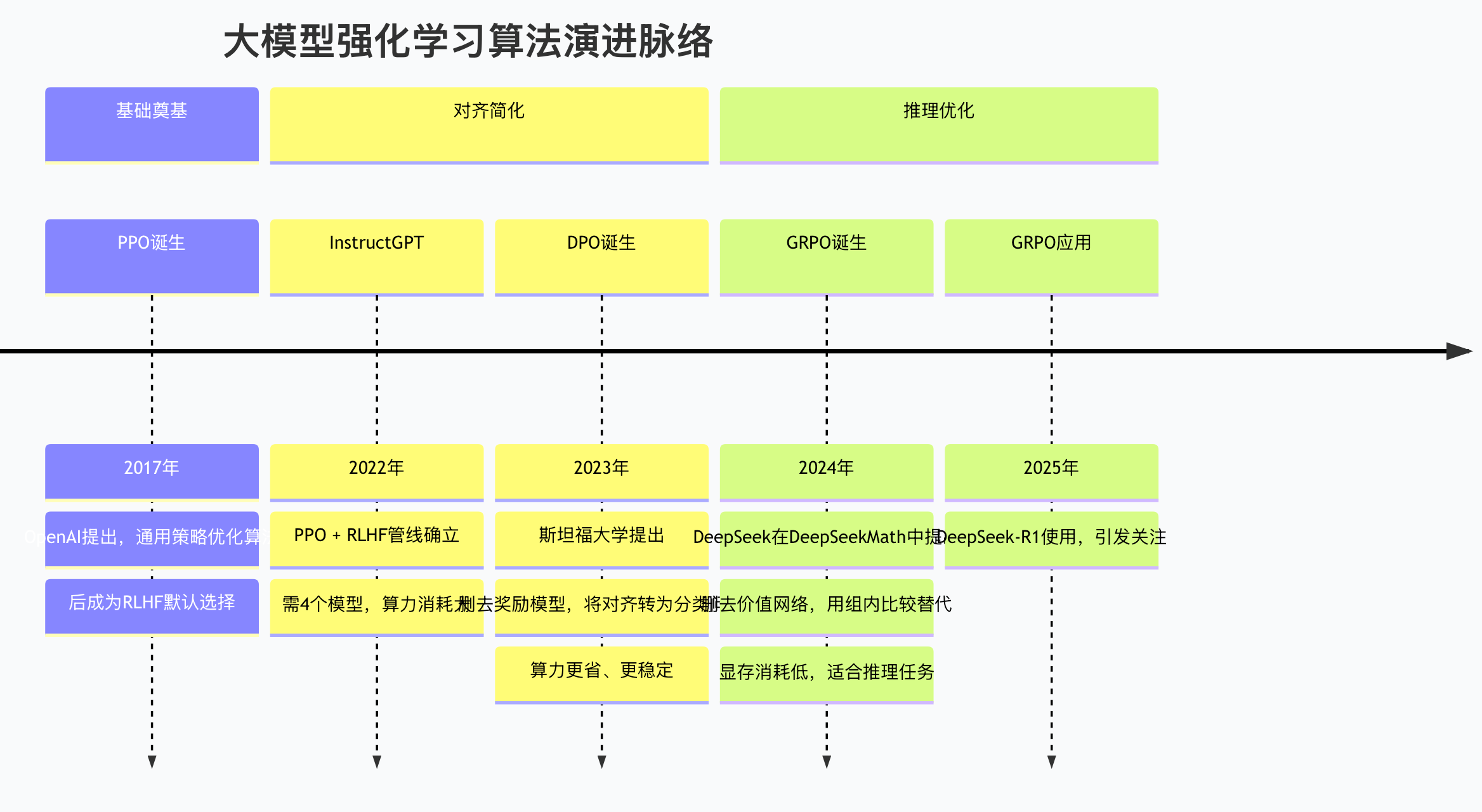
大模型时代的算法补充:
DPO(直接偏好优化) 可以看作是一种 基于策略(Policy-based)的变体。它跳过了显式的奖励模型,通过巧妙的数学变换,直接从偏好数据中优化策略,属于策略学习方法的一种高效实现。
PPO(近端策略优化) 则被归为 演员-评论家(Actor-Critic) 的经典代表。在大模型场景中,它通常与奖励模型配合,Critic(或优势函数)负责评估生成的完整回复,Actor则据此更新整个模型。
GRPO(群组相对策略优化) 是PPO的一种高效变体,同样属于Actor-Critic框架。它通过组内比较来简化优势估计,特别为LLM的推理任务优化了内存和计算效率。
第3层:具体算法(记住这些就够了)
┌─────────────────────────────────────────────────────────────────────────────┐
│ 初学者需要知道的算法清单 │
├─────────────────────────────────────────────────────────────────────────────┤
│ │
│ 【必须掌握 - 4个】 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Q-learning │ │ DQN │ │ PPO │ │ SARSA │ │
│ │ 表格型入门 │ │ 深度Q网络 │ │ 策略梯度主流 │ │ 同策略对比 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │
│ 【重要掌握 - 3个】 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ SAC │ │ A2C/A3C │ │ DDPG/TD3 │ │
│ │ 连续动作首选 │ │ 并行训练 │ │ 连续动作基础 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │
│ 【了解即可 - 3个】 │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ AlphaZero │ │ DPO │ │ HER │ │
│ │ 棋类AI │ │ LLM对齐 │ │ 稀疏奖励 │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────────────┘一张图搞定所有分类(初学者友好版)
强化学习算法
│
┌─────────────────────────┼─────────────────────────┐
│ │ │
▼ ▼ ▼
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ 离散动作 │ │ 连续动作 │ │ 模型已知 │
│ Discrete │ │ Continuous │ │ Model Known │
└───────┬───────┘ └───────┬───────┘ └───────┬───────┘
│ │ │
▼ ▼ ▼
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ Q-learning │ │ DDPG │ │ AlphaZero │
│ ↓ │ │ ↓ │ │ MuZero │
│ DQN │ │ TD3 │ │ │
│ ↓ │ │ ↓ │ └───────────────┘
│ Double DQN │ │ SAC │
│ Rainbow │ │ PPO* │
└───────────────┘ └───────────────┘
│ │
│ ┌────────────────────┘
│ │
▼ ▼
┌───────────────┐
│ Actor-Critic│ ← PPO、SAC、DDPG、TD3、A2C 都属于这一类
│ (两者结合) │
└───────────────┘注:PPO 既可以处理离散动作,也可以处理连续动作,是通用性最强的算法。
给初学者的学习路线图
第0步:先忘掉所有分类
↓
第1步:理解一个完整案例(比如:Q-learning 玩迷宫)
↓
第2步:按"动作类型"分类(离散 vs 连续)
↓
第3步:理解 Value-Based 和 Policy-Based 的区别
↓
第4步:知道 On/Off-Policy 是什么(理解即可,不用深究)
↓
第5步:按需深入学习具体算法一句话总结
对初学者来说,最好的分类不是学术上最严谨的,而是最能指导你"该学哪个、该用哪个"的分类。记住"离散动作用 DQN,连续动作用 PPO/SAC"就够了,其他分类都是进阶后慢慢补充的
按照环境是否已知划分:免模型学习(Model-Free) vs 有模型学习(Model-Based)
Model-free就是不去学习和理解环境,环境给出什么信息就是什么信息,常见的方法有policy optimization和Q-learning。
Model-Based是去学习和理解环境,学会用一个模型来模拟环境,通过模拟的环境来得到反馈。Model-Based相当于比Model-Free多了模拟环境这个环节,通过模拟环境预判接下来会发生的所有情况,然后选择最佳的情况。
一般情况下,环境都是不可知的,所以这里主要研究无模型问题。
按照学习方式划分:在线策略(On-Policy) vs 离线策略(Off-Policy)
On-Policy是指agent必须本人在场, 并且一定是本人边玩边学习。典型的算法为Sarsa。
Off-Policy是指agent可以选择自己玩, 也可以选择看着别人玩, 通过看别人玩来学习别人的行为准则, 离线学习同样是从过往的经验中学习, 但是这些过往的经历没必要是自己的经历, 任何人的经历都能被学习,也没有必要是边玩边学习,玩和学习的时间可以不同步。典型的方法是Q-learning,以及Deep-Q-Network。
按照学习目标划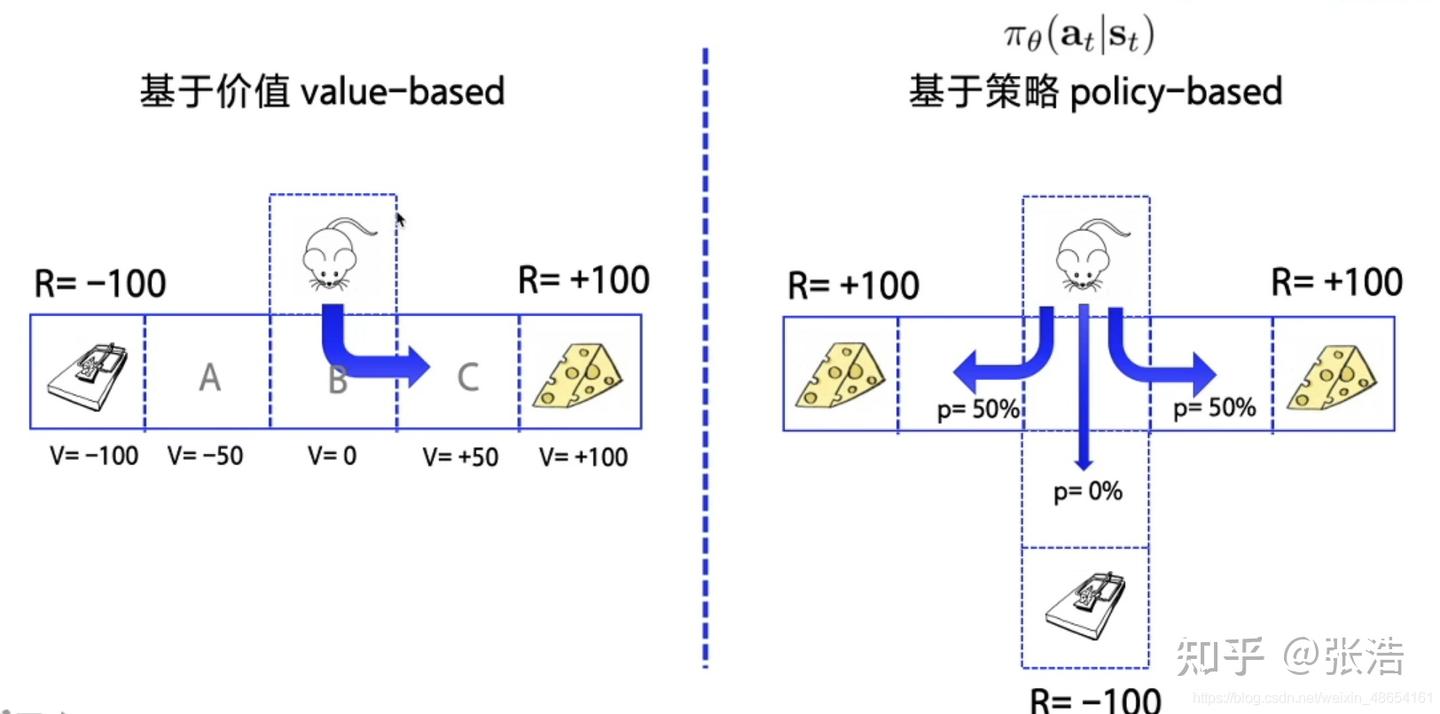
Policy-Based的方法直接输出下一步动作的概率,根据概率来选取动作。但不一定概率最高就会选择该动作,还是会从整体进行考虑。适用于非连续和连续的动作。常见的方法有Policy gradients。
Value-Based的方法输出的是动作的价值,选择价值最高的动作。适用于非连续的动作。常见的方法有Q-learning、Deep Q Network和Sarsa。
更为厉害的方法是二者的结合:Actor-Critic,Actor根据概率做出动作,Critic根据动作给出价值,从而加速学习过程,常见的有A2C,A3C,DDPG等。
经典算法:Q-learning,Sarsa,DQN,Policy Gradient,A3C,DDPG,PPO
四、强化学习经典算法
下面我们挑选一些有代表性的算法进行讲解:
基于表格、没有神经网络参与的Q-Learning算法
基于价值(Value-Based)的Deep Q Network(DQN)算法
基于策略(Policy-Based)的Policy Gradient(PG)算法
结合了Value-Based和Policy-Based的Actor Critic算法。
五、强化学习应用场景
强化学习核心算法速查表
大模型时期特有算法:
PPO、GRPO、DPO
按应用场景分类(快速选型)
按选择优先级排序(新手建议)
第1步(入门首选)
↓
Q-learning 或 DQN(理解基础概念)
↓
第2步(主流通用)
↓
PPO(最推荐,平衡性最好)
↓
第3步(连续动作)
↓
SAC 或 TD3(机器人/自动驾驶)
↓
第4步(特殊场景)
↓
AlphaZero(棋类)/ MADDPG(多智能体)/ DPO(LLM)参考文献
知乎:https://zhuanlan.zhihu.com/p/466455380
蘑菇书RL:https://datawhalechina.github.io/easy-rl/#/
菜鸟教程:https://www.runoob.com/ml/ml-basic-framework-of-reinforcement-learning.html